适用于 Kubernetes 的 Redis Enterprise 架构
本节概述了 Kubernetes 版 Redis Enterprise 的架构和注意事项。
Redis 基于几个重要概念制定了其 Kubernetes 架构。
分层架构
Kubernetes 是一款出色的编排工具,但它并非专为处理与操作 Redis Enterprise 相关的所有细微差别而设计。因此,它可能无法准确响应内部 Redis Enterprise 边缘情况或故障情况。此外,Kubernetes 编排在 Redis 集群部署之外运行,可能无法触发故障转移事件,例如在网络分离的情况下。
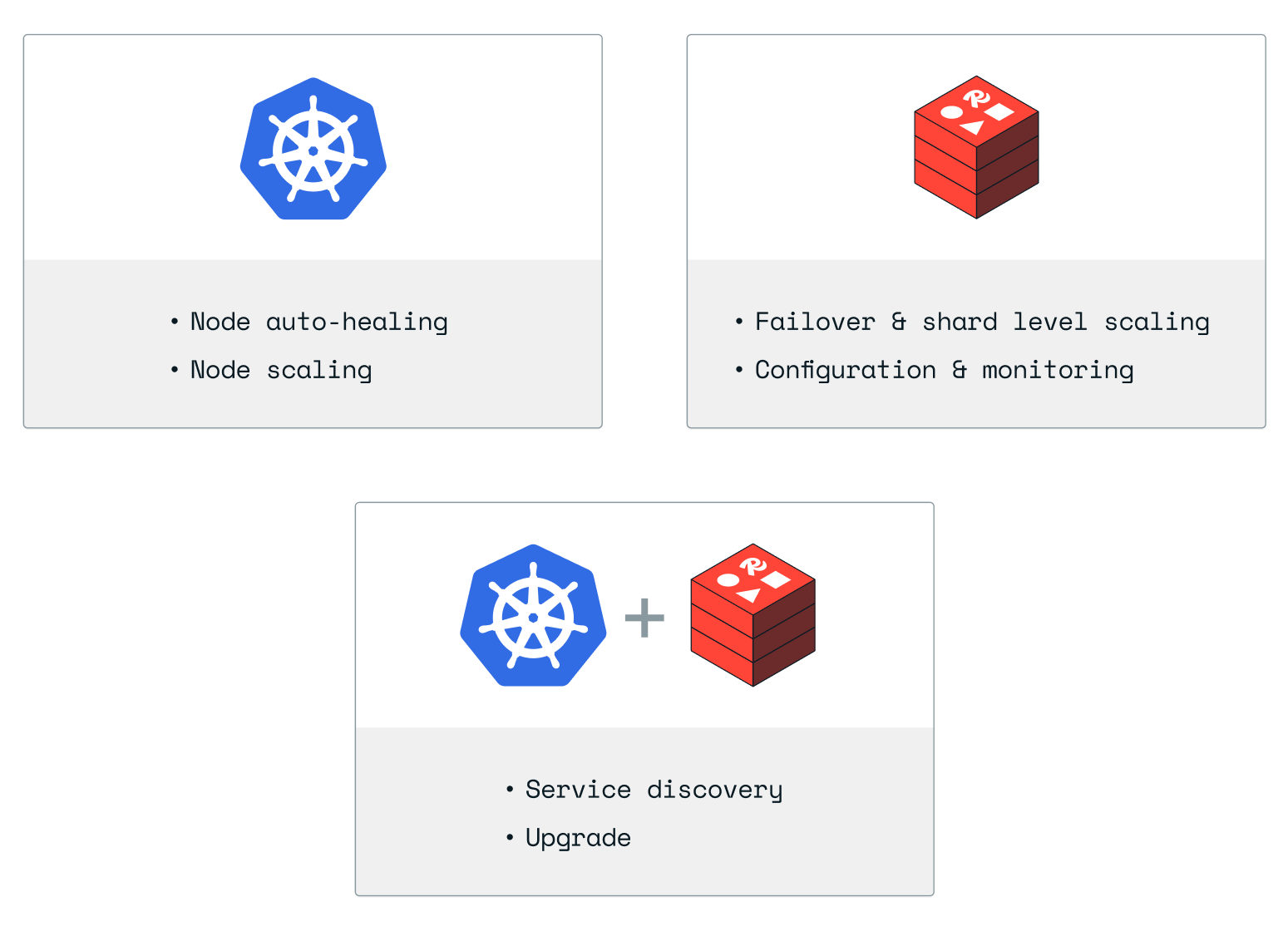
为了克服这些问题,Redis 创建了一种分层架构方法,将 Kubernetes 擅长的操作、Redis Enterprise Cluster 擅长的程序以及两者可以协调在一起的流程之间的职责进行划分。下图说明了这种分层编排架构:
基于运营商的部署
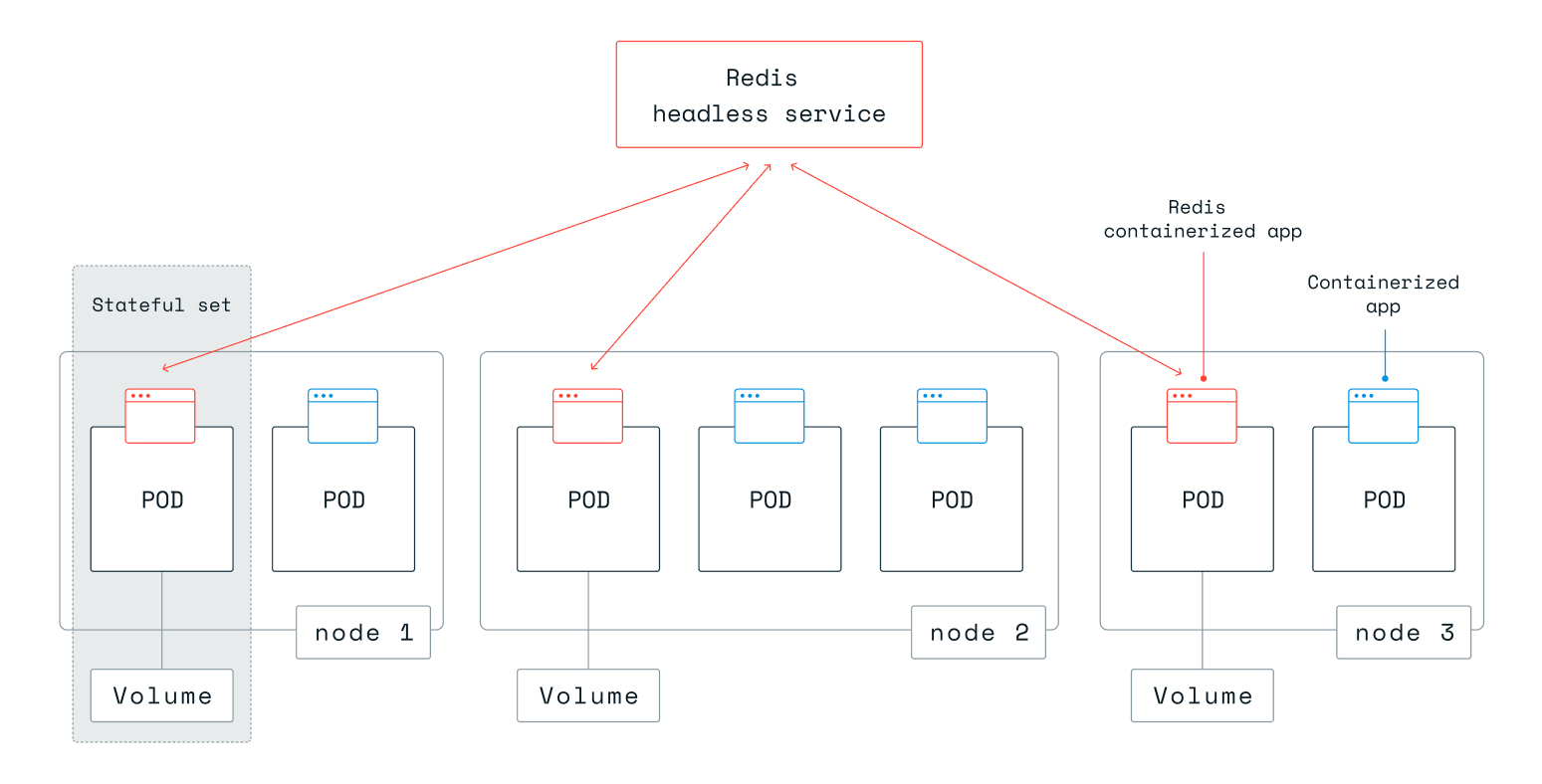
Operator 允许 Redis 在各种 Kubernetes 环境中维护统一的部署解决方案,即 RedHat OpenShift、VMware Tanzu(Tanzu Kubernetes Grid 和 Tanzu Kubernetes Grid Integrated Edition,以前称为 PKS)、Google Kubernetes Engine (GKE)、Azure Kubernetes Service (AKS) 和 vanilla (上游) Kubernetes。Statefulset 和反亲和性可确保每个 Redis Enterprise 节点都驻留在托管在不同 VM 或物理服务器上的 Pod 上。请参阅下图所示的设置:
网络附加持久存储
Kubernetes 和云原生环境要求存储卷通过网络连接到计算实例,以保证数据持久性。否则,如果使用本地存储,Pod 故障事件中可能会丢失数据。参见下图:
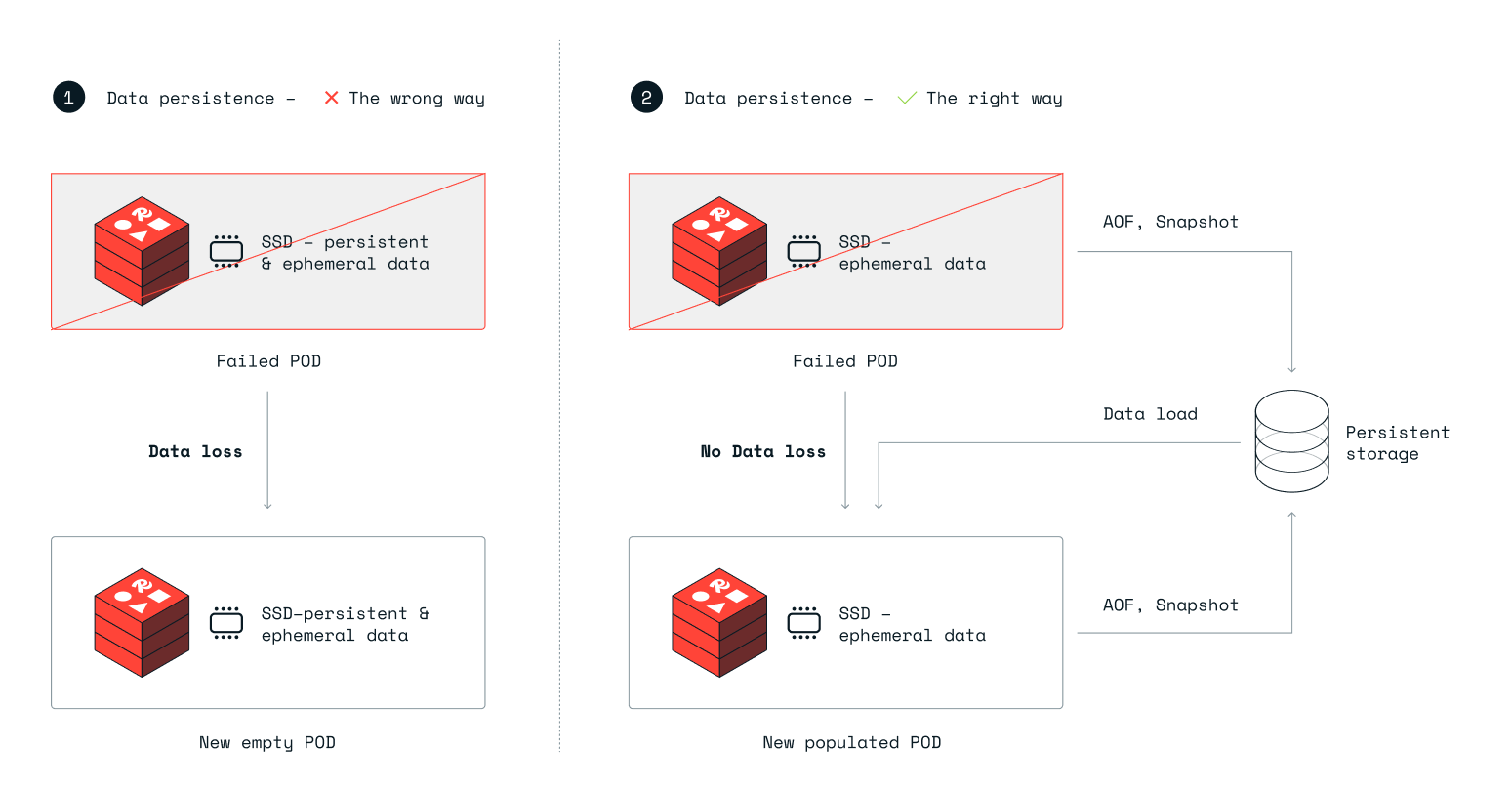
在左侧(标记为 #1),Redis Enterprise 使用本地临时存储来实现持久性。当 Pod 发生故障时,Kubernetes 会启动另一个 Pod 作为替代,但此 Pod 会提供空的本地临时存储,并且原始 Pod 中的数据现在会丢失。
在图的右侧(标记为 #2),Redis Enterprise 使用网络附加存储来实现数据持久性。在这种情况下,当 Pod 发生故障时,Kubernetes 会启动另一个 Pod 并自动将其连接到发生故障的 Pod 使用的存储设备。然后,Redis Enterprise 会指示在新建节点上运行的 Redis Enterprise 数据库实例从网络附加存储加载数据,从而保证持久的设置。
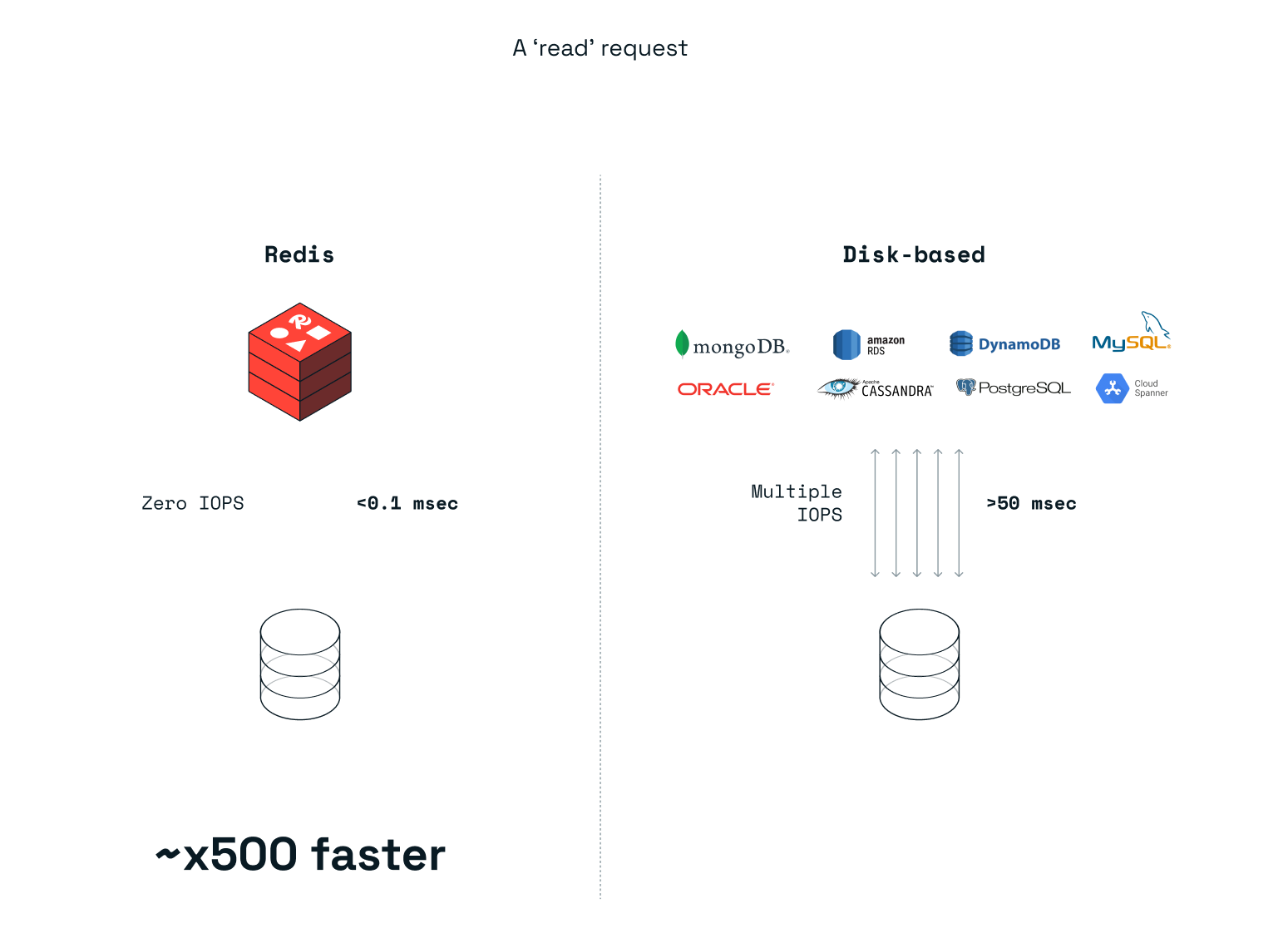
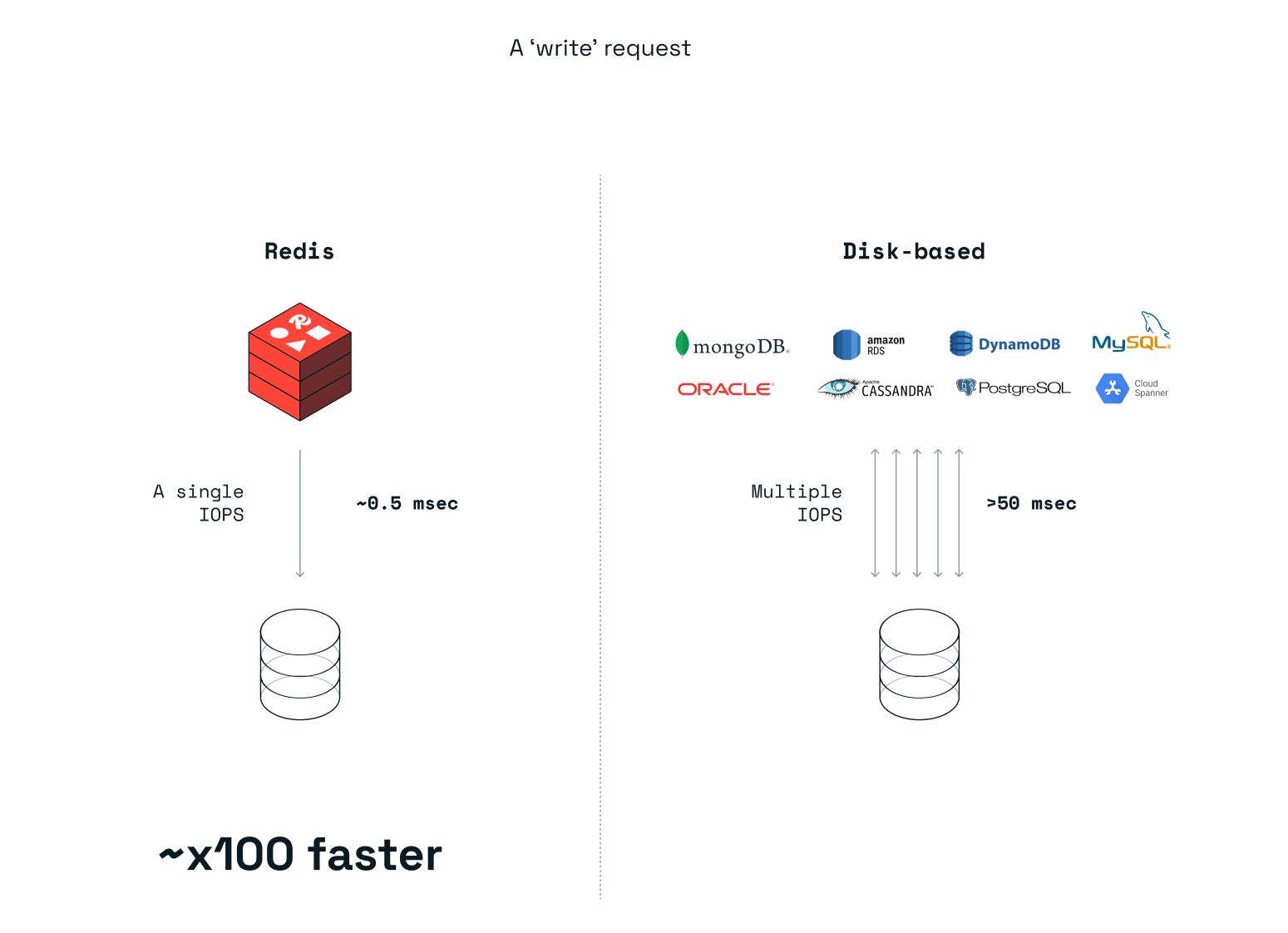
Redis Enterprise 不仅是一款出色的内存数据库,而且在使用持久存储方面也非常高效,即使用户选择将 Redis Enterprise 配置为将所有更改写入磁盘也是如此。与磁盘数据库相比,后者在每次读取或写入操作时都需要与存储设备进行多次交互(在大多数情况下),而 Redis Enterprise 在大多数情况下对写入操作使用单个 IOPS,对读取操作使用零 IOPS。因此,在典型的 Kubernetes 环境中可以看到显著的性能提升,如下图所示:
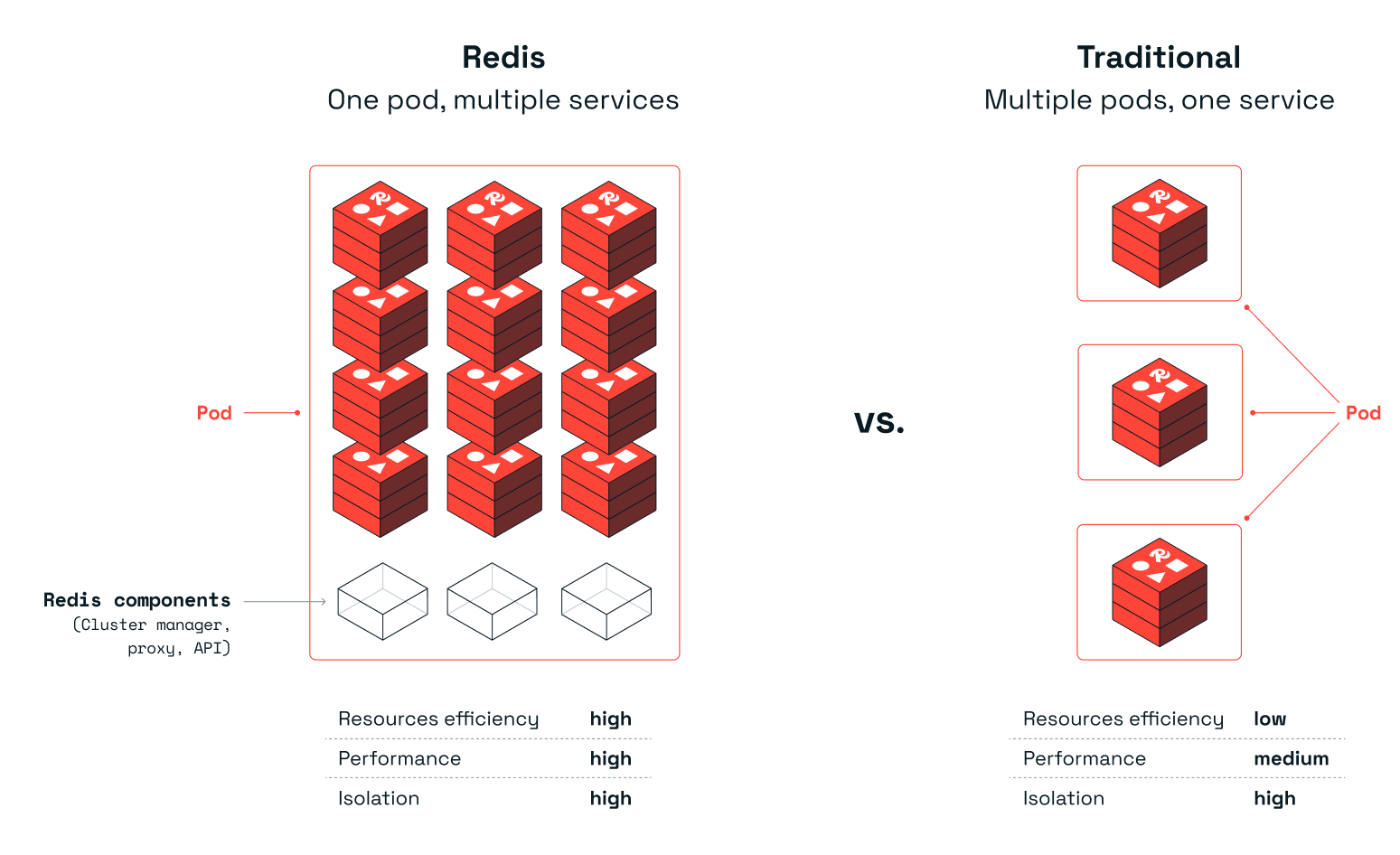
每个 pod 上有多个服务
每个 Pod 包含多个 Redis Enterprise 实例(多个服务)。我们发现,在 Kubernetes 上部署 Redis Enterprise 数据库的传统方法效率非常低,即每个 Pod 仅包含一个 Redis Enterprise 实例,同时保留一个专用 CPU。Redis Enterprise 速度极快,在许多情况下,只需使用一小部分 CPU 资源即可提供所需的吞吐量。此外,在多个 Pod 上运行具有多个 Redis Enterprise 实例的 Redis Enterprise 集群时,具有多个 vSwitch 的 Kubernetes 网络很快就会成为部署的瓶颈。因此,Redis 采用了不同的方法在 Kubernetes 环境中管理 Redis Enterprise。在单个 Pod 上部署多个 Redis Enterprise 数据库实例使我们能够更好地利用 Pod 使用的硬件资源(例如 CPU、内存和网络),同时保持相同的隔离级别。参见下图: